ETL vs ELT:全面解析數據集成方法的選擇與應用
在數據驅動的今天,數據集成是企業構建高效數據分析體系的關鍵環節。ETL(Extract, Transform, Load)和ELT(Extract, Load, Transform)作為兩種主流的數據集成方法,各自擁有獨特的優勢與適用場景。本文將深入探討ETL與ELT的定義、工作流程、關鍵區別以及在實際應用中的選擇因素。

一、定義與工作流程
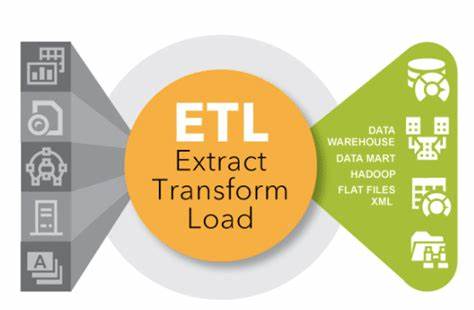
ETL(Extract, Transform, Load)
ETL是數據集成領域的經典模式,它按照“抽取-轉換-加載”的順序進行數據處理。具體來說:
抽取(Extract):從源系統(如數據庫、文件系統等)中抽取所需的數據。
轉換(Transform):對抽取的數據進行清洗、轉換、聚合等操作,以滿足目標系統的數據格式和質量要求。
加載(Load):將轉換后的數據加載到目標系統(如數據倉庫、數據湖等)中,供后續的數據分析或業務應用使用。
ELT(Extract, Load, Transform)
ELT是近年來隨著云計算和大數據技術的興起而逐漸流行起來的一種數據集成模式,它顛覆了傳統ETL的處理順序:
抽取(Extract)與ETL相同,從源系統中抽取數據。
加載(Load):直接將抽取的數據“原始地”加載到目標系統中,不進行任何預處理或轉換。
轉換(Transform):在數據加載到目標系統之后,利用目標系統強大的計算能力進行數據的轉換和處理。
二、關鍵區別
1.處理時機與地點:
ETL在數據加載到目標系統之前進行轉換,這通常需要專門的ETL工具或腳本在獨立的服務器上執行。
ELT則將轉換過程推遲到數據加載到目標系統之后,利用目標系統自身的計算能力進行數據處理,減少了數據傳輸和處理的時間成本。
2.性能與可擴展性:
ETL在處理大規模數據時可能面臨性能瓶頸,因為轉換過程可能占用大量計算資源。
ELT則能夠更好地利用云計算平臺的彈性擴展能力,根據數據處理需求動態調整計算資源,提高處理效率和可擴展性。
3.實時性:
ETL通常用于離線數據處理,難以滿足實時數據分析的需求。
ELT在處理實時數據流時更具優勢,因為數據一旦加載到目標系統即可立即進行轉換和分析。
4.技術復雜度與資源要求:
ETL需要專業的ETL工具和開發人員,對技術團隊的要求較高。
ELT則更依賴于目標系統的功能和性能,對技術團隊的要求相對較低,但需要對目標系統有足夠的了解和配置能力。
三、實際應用中的選擇因素
1.數據規模和復雜度:
對于大規模或復雜的數據處理需求,ETL可能更為適合;而對于數據量較小或實時性要求較高的場景,ELT可能更具優勢。
2.技術團隊和資源:
企業應根據現有技術團隊的能力和資源情況選擇合適的架構。如果團隊熟悉ETL工具并具有豐富的開發經驗,ETL可能是更好的選擇;如果團隊更擅長于數據倉庫或大數據平臺的操作和維護,ELT可能更合適。
3.業務需求和目標:
明確業務對數據處理的實時性、準確性、靈活性等方面的要求,選擇能夠滿足這些需求的架構。
4.成本考慮:
ETL和ELT在成本方面也存在差異。ETL通常需要購買專業的ETL工具并投入一定的開發成本;而ELT則可能利用現有的云計算資源和服務來降低成本。
綜上所述,ETL和ELT各有其優勢和適用場景。企業在選擇時應綜合考慮數據規模、復雜度、技術團隊能力、業務需求以及成本等因素,以構建高效、靈活、可擴展的數據集成體系。